
BigQueryとWorkflowsで特定の条件に該当するユーザーを抽出してLINE公式アカウントのオーディエンスを一括作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
リテールアプリ共創部@大阪の岩田です。
先日以下のブログを書いたのですが、せっかくなのでこれのGoogle Cloud版もやってみました。
やること
前述のブログの各種AWSサービスをGoogle Cloudのサービスに置き換えます。各サービスの対応はそれぞれ以下の通りです。
| サービス | AWS | Google Cloud |
|---|---|---|
| ストレージ | S3 | Cloud Storage |
| クエリ | Athena | BigQuery |
| ワークフロー | Step Functions | Workflows |
想定しているユースケースも先日のブログと同様です。何かしらのシステムが顧客の属性値とLINEユーザーIDの情報を定期的にCloud Storageバケットに出力していると想定し、出力されたファイルから条件に該当するユーザーIDを抽出し、LINEのMessaging APIを利用してユーザーIDアップロード用のオーディエンスを作成する一連の処理をWorkflowsで構築します。
環境構築
CDK TFを利用して環境を構築していきます。コードは以下の通りです。
まず各種設定値を取得する処理を作成します。実案件で利用する場合は複数環境の設定を切り替えて利用できるように拡張して下さい。
export type Config = {
projectId: string
location: string
lineClientId: string
}
export const getConfig = (): Config => {
return {
projectId: '<Google CloudプロジェクトのID>',
location: 'asia-northeast1',
lineClientId: '<LINE公式アカウントのChannel ID>'
}
}
続いてmain.tsです。シンプルに設定値の取得とスタックの作成のみを行います。
import { App } from "cdktf";
import { LineAudienceStack } from "./stacks/line-audience-stack";
import { getConfig } from "./config";
const app = new App();
const config = getConfig();;
new LineAudienceStack(app, "line_audience_stack", {
projectId: config.projectId,
location: config.location,
lineClientId: config.lineClientId
});
app.synth();
スタックのコンストラクタです。メイン処理はDwhConstructとWorkflowConstructに委譲しています。
import { Construct } from "constructs";
import { TerraformStack } from "cdktf";
import * as google from "@cdktf/provider-google";
import { DwhConstruct } from "../constructs/dwh";
import { RandomProvider } from "@cdktf/provider-random/lib/provider";
import { WorkflowConstruct } from "../constructs/workflow";
import { Config } from "../config";
type LineAudienceStackProps = Config;
export class LineAudienceStack extends TerraformStack {
constructor(scope: Construct, id: string, props: LineAudienceStackProps) {
super(scope, id);
const {location, projectId} = props;
new google.provider.GoogleProvider(this, 'GoogleProvider', {
project: projectId,
});
new RandomProvider(this, 'random-provider');
const dwh = new DwhConstruct(this, 'dwh', {
location,
});
new WorkflowConstruct(this, "workflow", {
location,
datasetId: dwh.datasetId,
lineClientId: props.lineClientId,
tableName: dwh.tableName,
});
}
}
DwhConstructの中身です。BigQueryからCloud Storageにクエリするための諸々のリソース作成に加え、テストに利用するためのファイルをアップロードする処理も記述しています。
import { Construct } from "constructs";
import * as google from "@cdktf/provider-google";
import { StringResource } from '@cdktf/provider-random/lib/string-resource';
import { resolve } from 'path';
import { readFileSync, readdirSync } from 'fs';
type DwhConstructProps = {
location: string;
}
export class DwhConstruct extends Construct {
readonly datasetId: string
readonly tableName: string
constructor(scope: Construct, id: string, props: DwhConstructProps) {
super(scope, id);
const { location } = props;
this.datasetId = 'line_dataset';
const dataset = new google.bigqueryDataset.BigqueryDataset(this, 'dataset', {
datasetId: this.datasetId,
friendlyName: 'Line Dataset',
description: 'Line Dataset',
location,
})
const bucketSuffix = new StringResource(this, 'randomString', {
length: 8,
special: false,
upper: false,
}).result;
const bucket = new google.storageBucket.StorageBucket(this, 'bucket', {
name: `line-audience-bucket-${bucketSuffix}`,
location,
forceDestroy: true,
})
const assetsDir = resolve(__dirname, '..', 'assets', 'line-users');
readdirSync(assetsDir).map((file, idx) => {
new google.storageBucketObject.StorageBucketObject(this, `object_${idx}`, {
bucket: bucket.id,
name: file,
content: readFileSync(`${assetsDir}/${file}`).toString(),
})
})
this.tableName = 'line_users';
new google.bigqueryTable.BigqueryTable(this, 'line_users_table', {
datasetId: dataset.datasetId,
tableId: this.tableName,
externalDataConfiguration: {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
sourceUris: [
`gs://${bucket.name}/*`
],
autodetect: false,
schema: JSON.stringify([
{
"name": "id",
"type": "STRING",
"mode": "REQUIRED",
"description": "LINEのユーザーID"
},
{
"name": "pref",
"type": "STRING",
"mode": "REQUIRED",
"description": "都道府県"
},
])
},
deletionProtection: false,
})
}
}
続いてWorkflowConstructの中身です
import { Construct } from "constructs";
import { Fn } from 'cdktf';
import { resolve } from 'path';
import * as google from "@cdktf/provider-google";
type WorkflowConstructProps = {
location: string;
datasetId: string;
lineClientId: string;
tableName: string;
}
export class WorkflowConstruct extends Construct {
constructor(scope: Construct, id: string, props: WorkflowConstructProps) {
super(scope, id);
const workflowsSa = new google.serviceAccount.ServiceAccount(this, 'workflow_sa', {
accountId: 'create-line-audience-sa',
displayName: 'Line Workflow Service Account',
});
new google.projectIamMember.ProjectIamMember(this, 'bq_data_viewer', {
role: 'roles/bigquery.dataViewer',
project: workflowsSa.project,
member: workflowsSa.member,
})
new google.projectIamMember.ProjectIamMember(this, 'bq_job_user', {
role: 'roles/bigquery.jobUser',
project: workflowsSa.project,
member: workflowsSa.member,
})
new google.projectIamMember.ProjectIamMember(this, 'gcs_obj_viewer', {
role: 'roles/storage.objectViewer',
project: workflowsSa.project,
member: workflowsSa.member,
})
new google.projectIamMember.ProjectIamMember(this, 'log_writer', {
role: 'roles/logging.logWriter',
project: workflowsSa.project,
member: workflowsSa.member,
})
const secretId = 'line_secret'
const secret = new google.secretManagerSecret.SecretManagerSecret(this, 'line_secret', {
secretId,
replication: {
auto: {}
}
})
new google.secretManagerSecretVersion.SecretManagerSecretVersion(this, 'line_secret_version', {
secret: secret.id,
secretData: 'デプロイ後に手動で書き換える',
lifecycle: {
ignoreChanges: 'all'
}
})
new google.secretManagerSecretIamMember.SecretManagerSecretIamMember(this, 'secret_accessor', {
secretId: secret.secretId,
role: 'roles/secretmanager.secretAccessor',
member: workflowsSa.member,
});
const templatePath = resolve(__dirname, '..', 'workflow.yaml');
const templateFile = Fn.templatefile(templatePath, {
lineClientId: props.lineClientId,
secretId,
dataset: props.datasetId,
table: props.tableName,
});
new google.workflowsWorkflow.WorkflowsWorkflow(this, 'Default', {
description: 'BigQueryのクエリ結果からLineのAudienceを作成するワークフロー',
serviceAccount: workflowsSa.email,
name: 'create-line-audience-workflow',
region: props.location,
sourceContents: templateFile,
});
}
}
準備できたらcdktf deployでデプロイしましょう。
デプロイできたらSecretManagerに新しいバージョンを追加し、LINE公式アカウントのChannel secretを登録してください。
ワークフローのポイント解説
最終的に作成されるワークフローは以下のような流れになります。
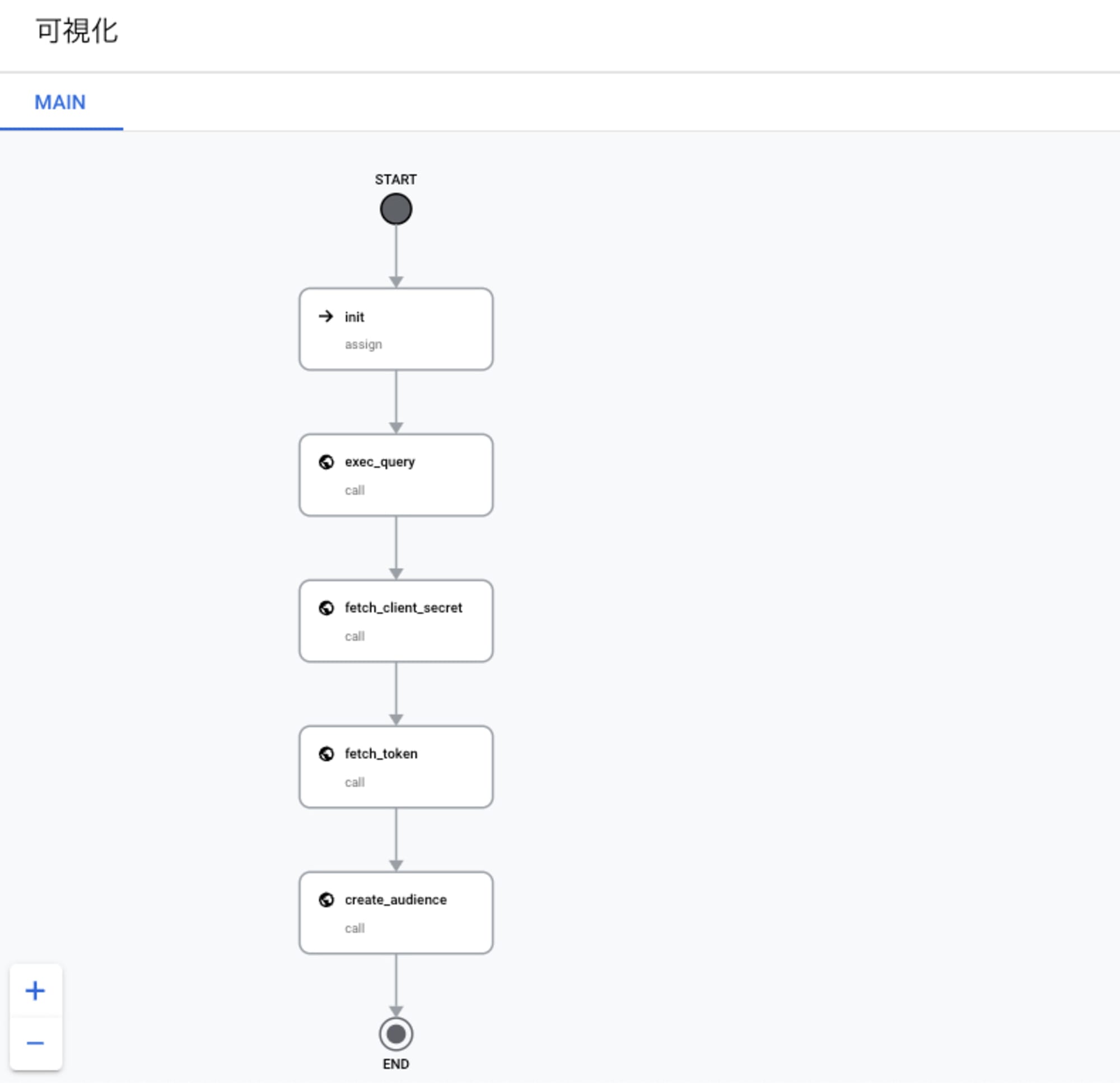
テンプレートに利用したファイルは以下の通りで、Terraformのtemplate機能を利用して一部の値を動的に埋め込んでいます。Workflowsの変数の機能とややこしいですが、${}で括られている部分がTerraformのtemplateで置換される箇所で、$${}で括られている箇所はデプロイ時に${}に置換されるためWorkflowsの変数として評価される箇所になります。
main:
params: [ args ]
steps:
- init:
assign:
- project_id: $${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- secret_id: ${secretId}
- exec_query:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: $${project_id}
body:
query: |
SELECT
TO_JSON_STRING(
ARRAY_AGG(
JSON_OBJECT('id', id)
)
) AS audiences
FROM
${dataset}.${table}
WHERE
pref = '兵庫県'
useLegacySql: false
result: query_result
- fetch_client_secret:
call: googleapis.secretmanager.v1.projects.secrets.versions.access
args:
name: $${"projects/" + project_id + "/secrets/" + secret_id + "/versions/latest"}
result: fetch_secret_result
- fetch_token:
call: http.post
args:
url: https://api.line.me/v2/oauth/accessToken
headers:
Content-Type: application/x-www-form-urlencoded
body:
grant_type: client_credentials
client_id: ${lineClientId}
client_secret: $${ text.decode(base64.decode(fetch_secret_result.payload.data)) }
result: fetch_token_result
- create_audience:
call: http.post
args:
url: https://api.line.me/v2/bot/audienceGroup/upload
headers:
Authorization: $${"Bearer " + fetch_token_result.body.access_token}
body:
description: Test From Google Cloud
uploadDescription: Google CloudのWorkflowから作成
audiences: $${json.decode(query_result.rows[0].f[0].v)}
各処理のポイントについて簡単に解説します。
BigQueryのクエリを実行(exec_query)
まずBigQueryのクエリを実行します。実行しているクエリは以下の通りで、条件に合致するユーザーIDをJSONの配列として取得し、最後に文字列にキャストします。
SELECT
TO_JSON_STRING(
ARRAY_AGG(
JSON_OBJECT('id', id)
)
) AS audiences
FROM
line_dataset.line_users
WHERE
pref = '兵庫県'
元テーブルのデータが以下の状態だとします。
| Id | pref |
|---|---|
| 123 | 大阪府 |
| 456 | 兵庫県 |
この場合クエリの実行結果は以下のような形になります。
| audiences |
|---|
[{\"id\":\"456\"}] |
結果をJSONではなく文字列にキャストしているところがポイントです。BigQueryのクエリ実行結果はTableRow型で返ってきます。クエリの実行結果がJSON型だとTableRow型のレスポンスは以下のような構造になります。
{"f":[{"v":[{"v":"{\"id\":456}"}]}]}
この構造だと後ほどLINE Messaging APIへのリクエストボディを組み立てる際にfやvが邪魔になるので、一旦文字列にキャストしてから後続処理で再度JSONにエンコードすることで取り扱いを簡単にしています。
LINE公式アカウントのChannel secretを取得(fetch_client_secret)
LINEのMessaging APIを呼び出すにはトークンが必要です。今回はLINE公式アカウントのChannel IDとChannel secretを利用し、Client Credentials flowに則ってトークンを取得します。先程Secret ManagerにChannel secretを登録しているので、ワークフローのSecret Manager API Connectorを利用してシークレット値を取得します。
LINE Messaging API用のアクセストークンを取得(fetch_token)
続いてLINEのトークンエンドポイントからアクセストークンを取得する処理です。前段のfetch_client_secretのレスポンスがbase64形式になっているので、以下の記述でbase64からデコード後にさらに文字列にデコードします。
client_secret: $${ text.decode(base64.decode(fetch_secret_result.payload.data)) }
LINEのMessaging APIでオーディエンスを作成(create_audience)
最後にLINEのMessaging APIを呼び出す処理です。BigQueruのクエリ実行結果がTableRow型で
{"f":[{"v":"[{\"id\":\"456\"}]"}]}
という形式になっているので、ここからquery_result.rows[0].f[0].vの指定でLINEユーザーIDの配列の文字列を抽出し、さらにjson.decodeでJSON形式にデコードしてリクエストボディにセットするのがポイントです
やってみる
実際にワークフローを実行してLINE公式アカウントのオーディエンスが作成されることを確認してみましょう。
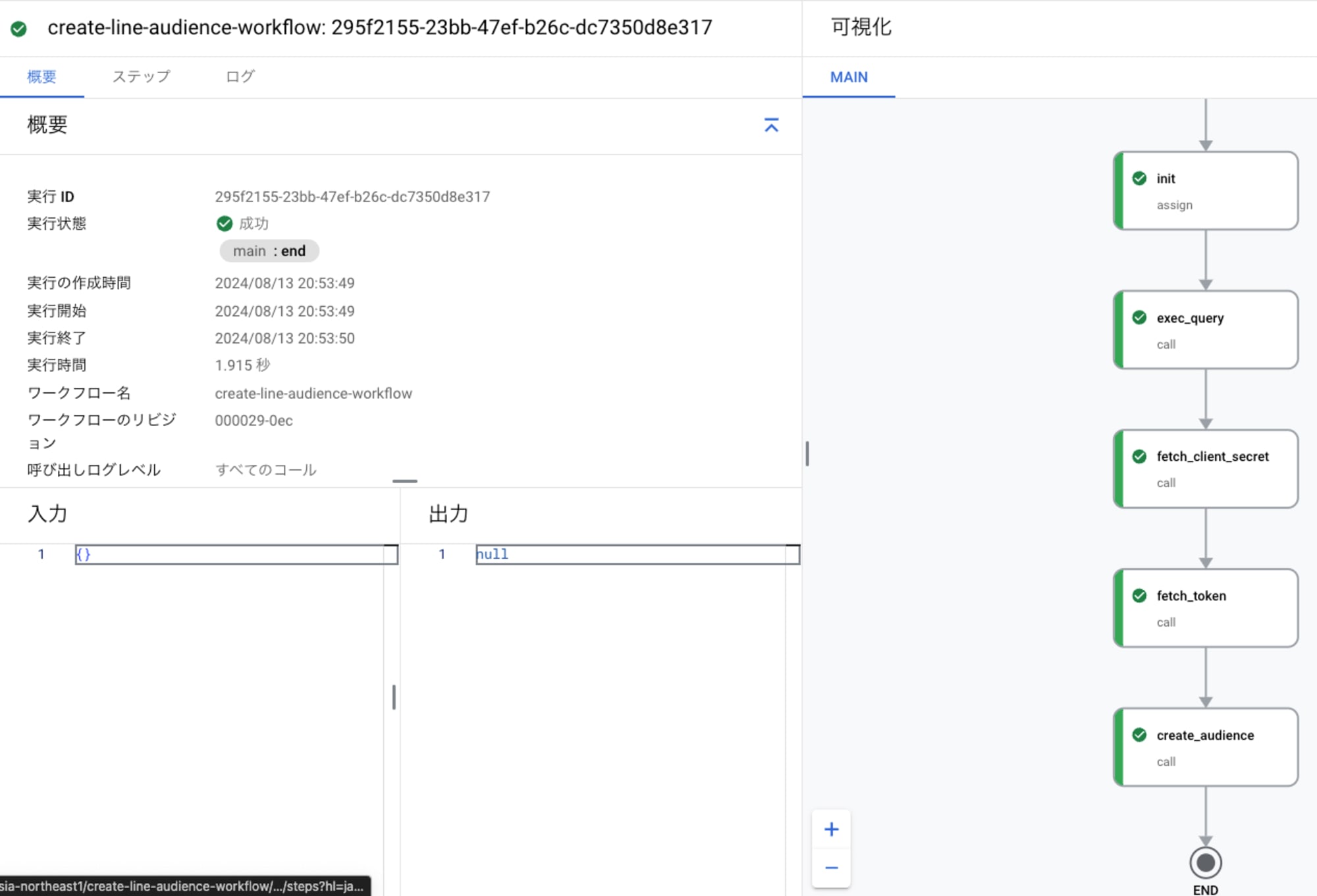
問題なく正常終了しました。このあとLINE公式アカウントの管理画面を確認すると...
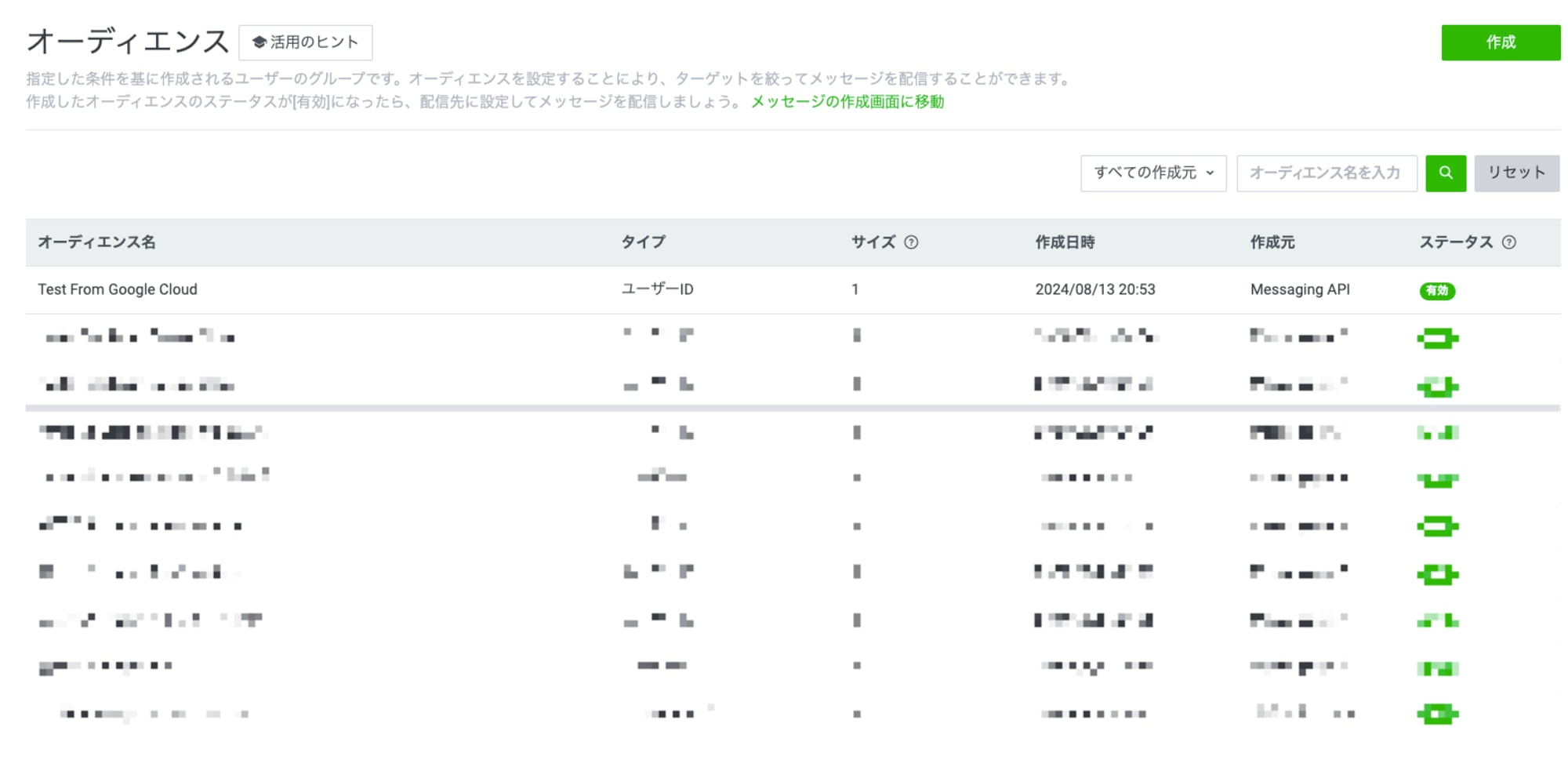
無事にオーディエンスが作成されていました!
まとめ
せっかくなのでBigQueryとWorkflowsを組み合わせてLINE公式アカウントのオーディエンスを作成してみました。AWSとGoogle Cloudそれぞれのサービスで同じような実装に挑戦してみましたが、それぞれ特徴があって面白いですね。
紹介したコードは以下のリポジトリで公開しています。








